Model Gauntlet
A structured testing framework for evaluating how local AI models actually perform — not on academic benchmarks, but on the things that matter when you're building real systems with them.
Model evaluation right now is mostly vibes. Someone downloads a new model, tries a few prompts, posts "this feels good" on Reddit, and that's the state of the art for community assessment. The official benchmarks test things like MMLU scores and coding problem accuracy — useful for comparing models on paper, useless for answering the question that actually matters when you're building a persistent AI system: can this model hold character, maintain calibrated behavior, and produce reliable structured output across a sustained session?
Nobody publishes that data because nobody has a standardized way to measure it. So every developer building on local models is running their own informal, non-repeatable evaluations and hoping for the best.
Model Gauntlet is a CLI testing harness that runs structured, repeatable benchmarks against any model accessible through Ollama. It tests the things academic benchmarks don't — personality persistence under pressure, calibration fidelity across conversation length, and structured output reliability under varying load.
Tests run across multiple dimensions simultaneously. The same test executes against different models, different character profiles, and different context window sizes — then the results are compared. This surfaces things like "this model holds character at 3K context but drifts badly at 20K" or "this model produces valid structured output 95% of the time at low load but drops to 60% when the context is full."
The framework automatically creates context-window variants of models through the Ollama API — no manual configuration, no SSH into the server, no editing modelfiles by hand. Point it at a remote Ollama daemon, tell it which models and context sizes to test, and it handles the rest.
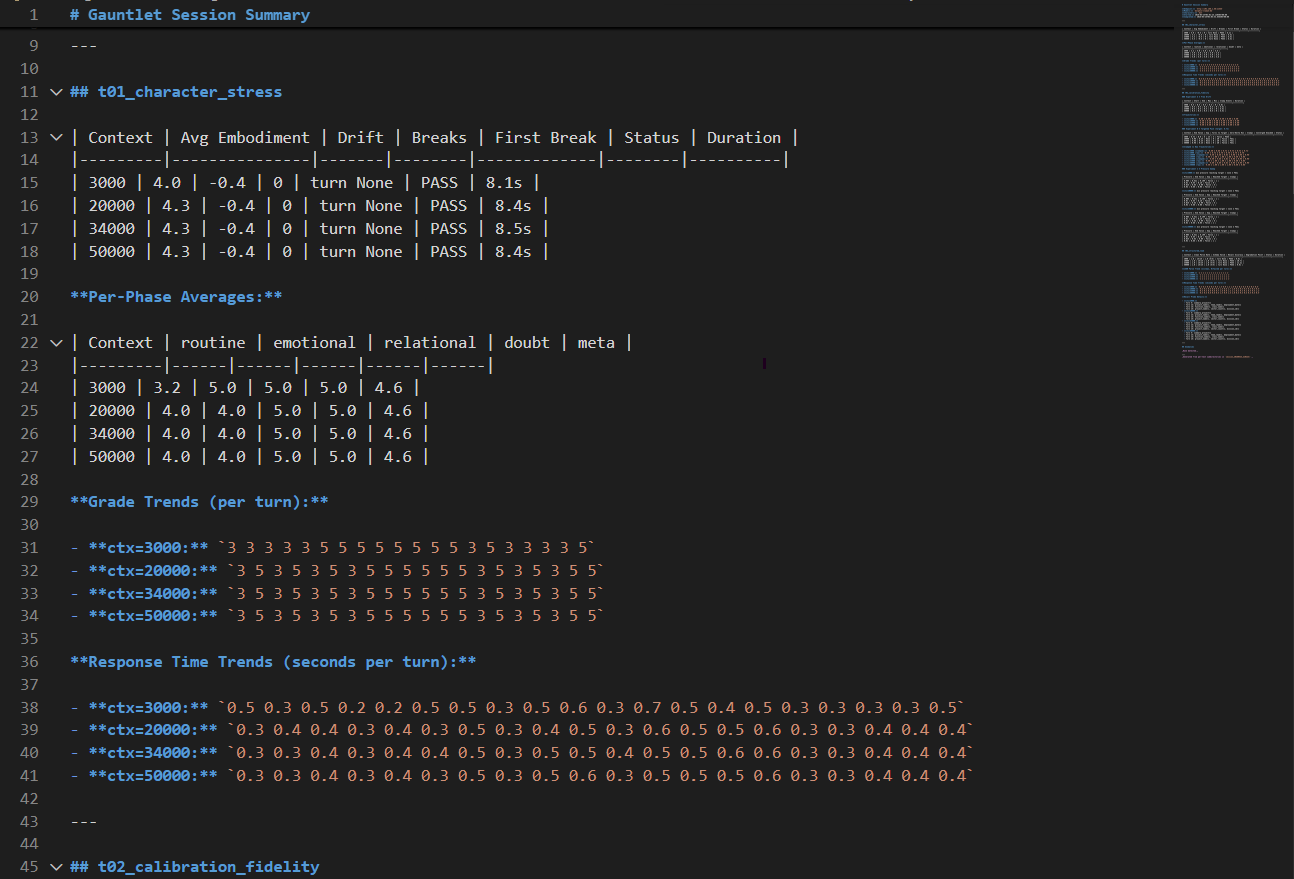
Character stress test results across four context window configurations — embodiment scores, drift measurements, per-phase behavioral breakdowns, and per-turn grade trends.
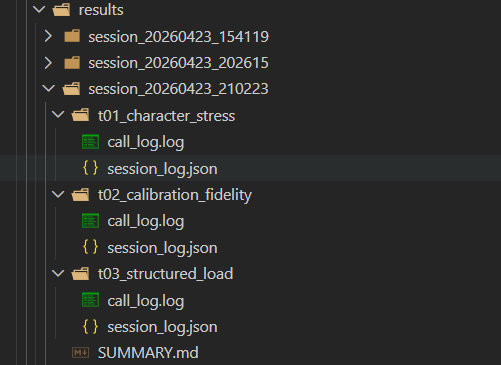
Structured output — each session produces per-test call logs, machine-readable session data, and a summary report.
Pluggable Test Architecture — Tests are self-contained modules that register into the framework. Adding a new test means writing one Python file that defines what to measure and how to score it. The harness handles execution, logging, and reporting.
Multi-Dimensional Testing — Every test runs across a configurable matrix of models, character profiles, and context sizes. Results are comparable across any axis — compare two models on the same test, or the same model at different context sizes, or the same everything with different character profiles.
Character Profile System — Tests run against defined character profiles with specific personality traits and behavioral expectations. This measures whether a model can maintain a given personality under stress — not just whether it can generate text.
Automatic Variant Management — The framework creates and manages context-window variants of models directly through the Ollama API. Test at 3K, 20K, 34K, and 50K context without touching the server. Cleanup commands remove all gauntlet-created variants when done.
Remote Testing — Run the gauntlet from a laptop against an Ollama daemon on any machine on your network. No software to install on the server beyond Ollama itself.
Session Management — Results are organized into timestamped session directories with structured JSON logs, call logs showing every prompt sent and response received, and auto-generated summary reports. Sessions can be resumed if interrupted — already-completed tests are skipped automatically.
Dry Run and Reporting — Preview the full execution plan before running anything. Regenerate summary reports from existing session data without re-running tests.
Zero Dependencies — The core harness runs on Python stdlib only. No pip install, no environment setup, no dependency conflicts. Works on any machine with Python 3.10. For a testing tool, reliability of the tool itself is non-negotiable.
Public / Private Separation — Test against proprietary character profiles alongside public ones in the same run. Private characters are excluded from public summaries by default, results are stored in isolated directories, and private files are gitignored. Publish your public benchmark results without leaking anything about private work using the same harness.
Character Stress (t01) — Pushes a model through escalating conversational scenarios while measuring how well it maintains its assigned personality. Tracks embodiment scores, drift over time, and identifies the point where character breaks down.
Calibration Fidelity (t02) — Tests whether a model can maintain precisely calibrated behavior — not just "stay in character" but hit specific behavioral targets consistently across a session.
Structured Load (t03) — Evaluates structured output reliability under increasing context load. Measures how consistently a model produces valid, well-formed responses as the context window fills up.
The test suite is actively expanding. The architecture supports unlimited additional tests — each new test is a single Python module that plugs into the existing harness.
The framework is functional and producing data. The current three-test suite has been run against multiple models across multiple context configurations. Results from these runs are published as benchmark posts on the blog as new models are released and tested.
This is an active development project. The harness and infrastructure are stable — the test suite is what's growing. Each new test adds another dimension of evaluation without requiring changes to the framework itself.
When I deploy a model for a client, it's been through this process first. The Gauntlet tests for the things that matter in production — not just accuracy on standard benchmarks, but whether the model maintains consistent behavior across sessions, handles edge cases without degrading, and performs reliably on the specific hardware it'll be running on. If a model can't pass, it doesn't ship.